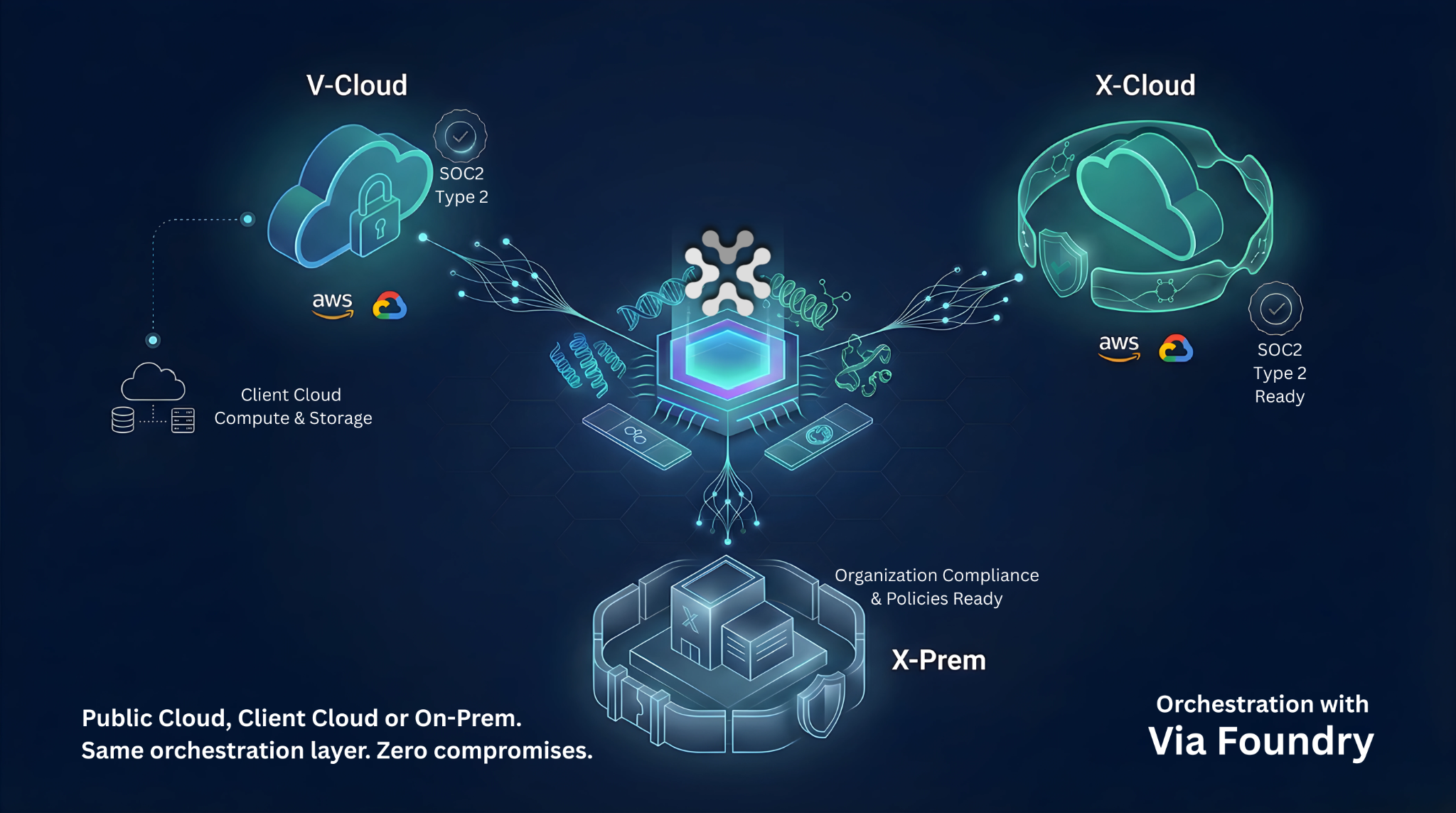
And How Foundry Solves The Five Fracture Points of Reusability
We all know the pain of trying to re-run an old pipeline. The folders are there. The code is… somewhere. The dependencies have changed. The person who wrote it now works in climate tech.
Reusability in bioinformatics isn’t just about good intentions. It’s about system design. And right now, most teams are trying to stitch together a reusable workflow from a pile of disconnected tools. GitHub here. Nextflow and Containers there. Docs in someone’s Google Drive.
And it mostly works. Until it doesn’t.
One of the principal goals of Foundry was to address the reusability challenge. It does not reinvent the wheel in any one category, but rather brings all the wheels under one chassis and keeps them rolling together.
Let’s walk through the five fracture points of reusability and look at how Foundry handles each.
1. Code Modularity
The Problem:
Most bioinformatics code isn’t modular, it’s meant to be run once by the person who wrote it. Sure, they meant to modularize, but they were pulled in a lot of different directions, so they shipped a one-off because they didn’t have the time.
How Foundry Helps:
Foundry treats pipelines like GitHub treats software: every change is tracked, versioned, and stored with context. You’re not just managing code, you’re managing reproducible scientific processes. Scientists can build reusable modules, define inputs and outputs, share with others, and allow them to build variations without breaking the original.
2. Environment Drift
The Problem:
R and Python environments are fragile. One library difference or environment misalignment and your analysis may return a different result.
How Foundry Helps:
Foundry enforces containerization - this isn’t a suggestion but rather, the rule. That means every input, dependency, and output is explicitly defined and packaged. Teams stop cutting corners because the platform won’t let them. This does take more time initially, but saves a lot in crises down the road.
3. Data and Metadata Provenance
The Problem:
Most pipelines assume the data is “just there.” Until it’s not. Then it’s chaos.
How Foundry Helps:
Every file used in Foundry must have a defined path. That doesn't prevent someone from moving a file, but it does mean that if something breaks, you have a breadcrumb trail. The data lineage is embedded in the run history so you know where data came from, even years later.
Metadata is equally important, yet many teams still manage it in discrete files that are tracked and versioned separately. Anyone who has downloaded a dataset from GEO (or similar) knows this pain well. One variation in the naming scheme, unfortunately more the rule than the exception, and you’re in for a bad day. Foundry helps by creating a linked entity that both tracks metadata versioning and connects it to the underlying dataset.
4. Run Logging and Output Tracking
The Problem:
Run tracking is often a custom job. Some teams use spreadsheets, others rely on naming conventions, and visibility varies wildly. There’s always a gradient. But when something critical depends on an individual's habits and memory, you’re gambling with your science.
How Foundry Helps:
Foundry logs everything: pipeline versions, parameters, inputs, outputs, containers, run status, and user actions. Run logging isn’t new. What’s new is how tightly it’s integrated with every other piece of context. When you revisit a run, you don’t just see what happened; you see how, when, and why. That level of insight isn’t just nice, it’s a 10x quality-of-life boost for anyone doing science at scale.
5. Collaboration and Handoff
The Problem:
Most bioinformatics work is trapped in individual heads and personal machines.
How Foundry Helps:
Foundry turns pipelines into shared infrastructure. Developers can collaborate on modules and pipelines with clear separation and version control. End users like scientists, analysts, downstream teams, can remix validated components without needing to dive into the codebase. Everything they do is tracked, auditable, and reproducible. Handoffs stop being a liability and start becoming part of the design.
This Isn’t About “One New Thing”
None of these features are novel by themselves. GitHub does versioning. Docker does containers. Slack does collaboration. But bioinformatics needs all of them working together, contextually aware, pipeline-native, and friction-free in order to truly scale.
That’s what Foundry provides: an operating system for reproducible science.
We still love GitHub. We still love Nextflow. We are on Slack 24/7. Foundry doesn’t replace these but instead it orchestrates them.
The ROI Is Two-Fold
- Today: You save time, avoid firefighting, and unblock teams faster.
- Tomorrow: You eliminate reanalysis meltdowns, broken handoffs, and data that disappears into the void.
That’s what it means to make reusability the default and not the exception.
Schedule time to see a demo here: https://www.viascientific.com/schedule-a-call