
Modern bioinformatics with Via Foundry: One orchestration layer, flexible deployment paths
Early-stage bioinformatics workflows can get away with ad-hoc scripts, notebooks, local data files and manual execution. The approach however breaks very quickly as the scale of code, workflows, data, teams and collaboration grows. Bioinformatics at scale isn’t about running a few specific tools and more about orchestrating many moving parts repeatedly and reproducibly.
Data ingestion, preprocessing pipelines, analytical tools, custom code, and AI/ML models all need to run in the right order, with the right parameters, on the right infrastructure.
When orchestration breaks down, science slows down. Pipelines become fragile, reproducibility suffers, and teams spend more time managing execution than interpreting results.
Most bioinformatics teams don’t get to choose where their workloads run. Data policies, security rules, and cost constraints usually decide that for them.
What teams should be able to choose is how they orchestrate workflows. Changing where compute runs should not mean changing how pipelines are defined, managed, and operated.
Inspired by this idea, Via Foundry supports three deployment modes. What changes is where workflows run and data gets stored, not the way individual scientists and teams work.
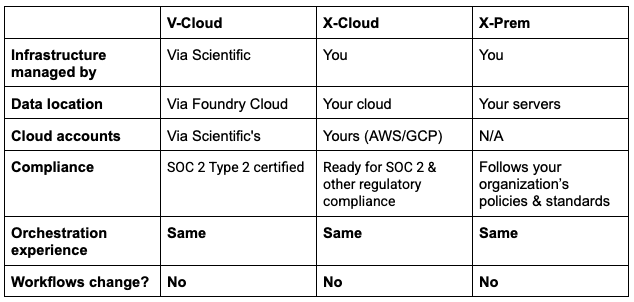
V-Cloud: Managed Cloud
Run pipelines, tools, code, and AI workloads on Via Foundry in a managed cloud environment. Great when teams don’t want to worry about cloud & application management. Via Foundry’s SOC 2 compliance ensures that data, code and other assets stay protected, no matter what.
If needed, teams can also bring their own compute and storage. This makes V-Cloud hybrid when required, without changing workflows.
Use Foundry V-Cloud when:
- You want to move fast
- You need elastic scale
- You want minimal infrastructure management
X-Cloud. Your Cloud Accounts
Bring your own cloud to run workloads on Via Foundry inside your own AWS or GCP accounts. You control networking, IAM, billing, and data boundaries. We set up Via Foundry on your own cloud and let you manage the cloud and access. The flexibility still comes with SOC2 compliance to ensure that your data and other assets stay protected on the cloud.
Workflows don’t change, but you have flexibility on where they run.
Use this when:
- You need full control over cloud infrastructure
- Data must stay in your cloud environment
X-Prem. Your On-Prem Infrastructure
We understand patient data security, especially of biomedical origin, is of utmost concern for many organizations. X-Prem deployment allows running workloads entirely on your own servers or clusters. This includes regulated, air-gapped, or sensitive environments.
Again, workflows don’t change, only the execution/data location changes.
Use this when:
- Data cannot leave your infrastructure
- You operate in regulated or restricted environments
- You already have on-prem compute/storage you need to use
You choose where your bioinformatics workloads run. ViaFoundry keeps orchestration consistent.
The principle underneath
There's a simple idea behind all three models.
Orchestration should be independent of infrastructure. How your scientists define, manage, and run pipelines shouldn't be dictated by where the compute lives.
Whether your data policies require on-prem, your team prefers managed cloud, or your organization runs its own AWS accounts, Via Foundry delivers the same orchestration experience across all three. Same workflows. Same interface. Same reproducibility. The deployment model is a reflection of your organization's needs, not a constraint on how your science gets done.
Public cloud, client cloud, or on-prem. Same orchestration layer. Zero compromises.
You choose where your bioinformatics workloads run. Via Foundry keeps orchestration consistent.





